这几天,一个叫“大语言模型进化树”的动画在学术界疯传:
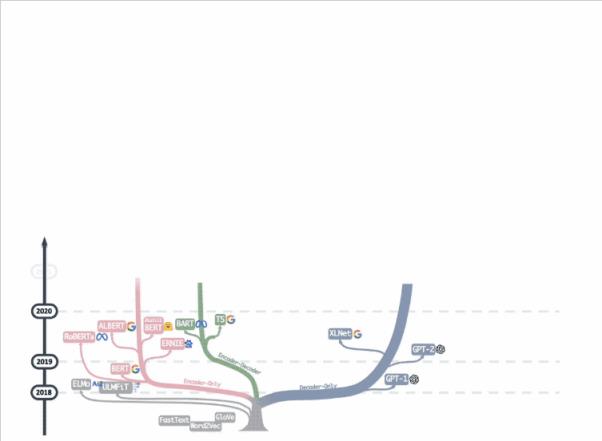

它清晰地梳理了2018-2023年五年间所有大语言模型的“代表作”,并将这些模型架构分为三类,演进结果一目了然:
在业界颇具影响力的 Google BERT从一开始就走到了一个“岔路口”,现在在生成AI领域濒临淘汰;
与Google和meta的“多线布局”不同,OpenAI从GPT一号开始就坚定地走在技术路线的某一条,现在成功地走在了这条路线的最前沿…
有网友调侃说,在大模式成功之前,大家只是在参与一场“赌博游戏”:

有网友感叹,很难想象两年后会演变成什么样。
我们拿起它,发现这张图片最初来自最近的一篇总结论文“在实践中使用大模型的力量”:
本文不仅阐述了现代大语言模型LLM的五年发展历程,还对目前大家最焦虑的关键问题“如何选择LLM”进行了详细的回答。
比如在自然语言理解的任务中,微调模型通常是比LLM更好的选择,但是LLM可以提供强大的泛化能力;在知识密集型任务中,LLM学到了更多真实世界的知识,因此比微调模型更适合。
一切都浓缩成一幅画,不要太清晰。
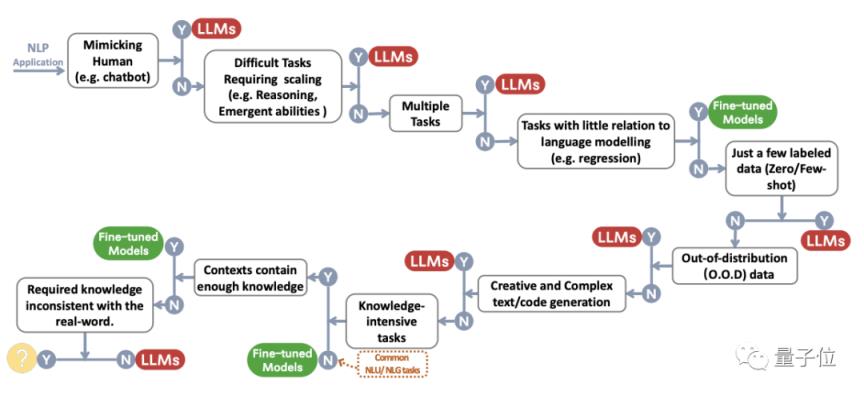
论文整体分为三个部分,详细介绍了大语言模型是如何开发的(模型实用指南),大模型的性能是如何受到影响的(数据实用指南),在什么场景下使用什么样的模型(NLP任务实用指南)。
让我们一个一个来看看。
“伯特学派”和“GPT学派”分为两部分。
首先,让我们解释一下LLM的进化史,这是本文中模型的实用指南。
根据该论文,大模型的发展可以主要分为两类。作者将其命名为“伯特学校”,以及“GPT学校”:
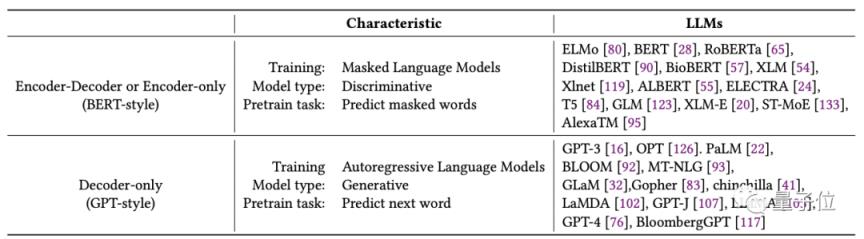
其中“伯特学派”以模型中的编码器架构为特征,可分为编码器-解码器和仅编码器架构。
“GPT学派”主张扔掉编码器,只保留解码器——只保留在架构中。
起初,伯特派占了上风。而以BERT为代表的编码器专用路线发展惨淡,到2020年相关研究将逐渐消失。
随后,GPT-3的出现彻底改变了大语言模型领域的风向,以OpenAI为代表的“GPT学派”开始发展壮大,成为发展最为顺利的LLM。
按照这个思路,作者将其制作成一个完整的树形图,记录了这些年大模型主要路线的发展和兴衰。
而这张图也成为了谷歌和OpenAI在大模型上的战争的“记录图”。
显然, Google 在三个方向有很多布局:只有解码器,只有编码器和编解码器。然而,今天,大模型仍然是“一条路到底”,只有解码器专用的OpenAI占上风:
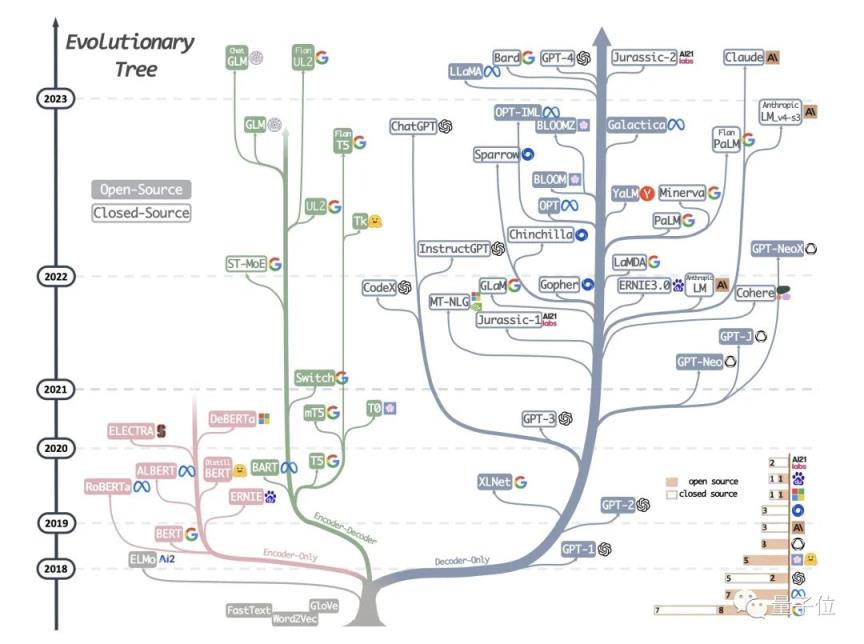
△图中有个bug,ALBERT是谷歌开发的
但对比之下,我们也可以发现,大模型整体呈现出“越来越封闭”的状态,这在很大程度上是“开放”AI的表现。
不过在这些大厂里,meta开源还是做得不错的,只有几十个人的HuggingFace成为了一支重要力量:
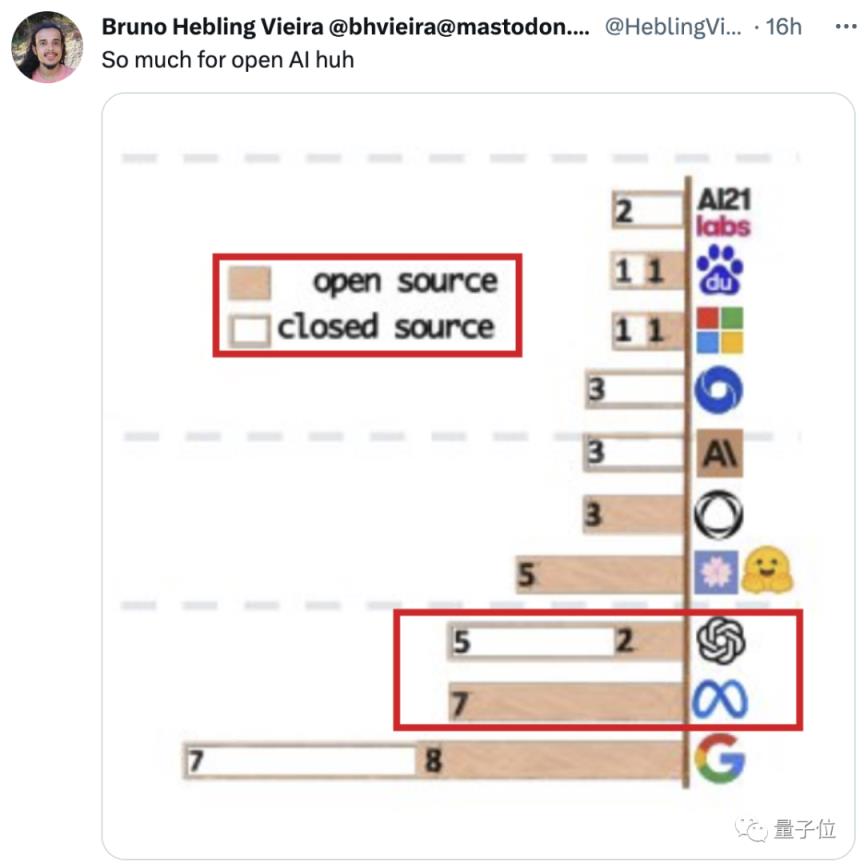
当然,这并不意味着伯特学派整体上已经落后了。毕竟编解码器的分支已经发展的很好了,包括清华GLM和Google T5,都是这个领域有代表性的开源模式。
未来这些LLM路线的发展速度是否会发生变化,还是未知数。

那么,影响大模型性能的关键因素是什么呢?
如何判断LLM的表现?
本文认为,影响LLM性能的关键因素仍然是数据。
什么样的数据?
根据LLM的不同阶段,数据类型也主要分为三种,包括预训练数据、微调数据和测试/用户数据。
不同的数据类型对模型的影响不同,甚至可以直接决定大模型的最佳适用范围。本文在《数据实用指南》中有具体解释。
首先是预训练数据。它相当于一个大语言模型的“底子”,不仅决定了LLM的“语言技能”,也极大地影响了LLM在下游任务中的表现。
一方面,LLM的“语言技能”是指大语言模型理解单词的知识、语法、句法和语义的能力,以及语境和生成连续文本的能力。
为了锻炼LLM的这部分能力,数据需要充分展现人类的知识、语言和文化。
另一方面是LLM在下游任务中的表现,对于如何选择LLM应用思路起着至关重要的作用。
为了锻炼LLM的这部分能力,需要考虑训练前数据的多样性,尤其是完成特定下游任务所需的“特定”数据,比如用社交媒体数据训练的LLM的问答能力,用代码数据训练的LLM的逻辑和代码填充能力等。
其次是微调数据。这部分数据经常用来“调试”某个特定任务的性能,分为零标记数据、少量标记数据和大量标记数据。
其中,零标签数据通常用于零炮学习,即希望大模型能够完成从未有过的任务,具有更强的“推理能力”;
少量的标记数据主要用于指导大模型的推理能力,提高一些小样本任务的性能。类似的方法还有元学习和迁移学习。
大量的标记数据用于提高特定任务的性能。当然,在这种情况下,微调模型和LLM都可以考虑使用。
最后,测试/用户数据。这部分数据用来缩小模型训练效果和用户需求之间的差距。典型的方法包括RLHF,即人类反馈强化学习,可以显著增强LLM的泛化能力。
知道了三类数据对模型的不同影响,在实际任务中如何选择对应的模型?
LLM还是微调模型?对六种具体情况的分析
接下来是本文的重点部分:自然语言处理任务实用指南。
在实际的下游任务中,是选择直接使用只经过预训练的大模型LLM,还是使用经过特定数据集微调的较小模型?
具体情况具体分析。
首先我们来看传统自然语言理解(NLU) 的任务,包括文本分类、用于知识图谱构建的命名实体识别(NER)、自然语言推理蕴涵预测等
首先得出结论:
具体来说,在大多数自然语言理解任务中,如果这些任务包含丰富且注释良好的数据,并且在测试集上几乎没有超出分布的示例,则微调模型的性能会更好。
但是对于不同的任务和数据集,它们之间的差距并不完全相同。
比如在文本分类上,LLM只是略逊于微调模型;在情感分析中,LLM的表现和微调模型一样好;在毒性测试中,所有LLM都很差。
笔者认为这个结果和LLM的指令或者提示设计有关,微调模型的上限真的很高。
当然,也有LLM擅长的事情。一种是杂文分类,需要处理各种不相关的内容,更接近真实世界。另一种是对抗性自然语言推理(ANLI)。LLM对这类分布外、标注稀疏的数据有很好的泛化能力,但对模型的微调不好。
后跟生成任务,包括两种类型:
第一种侧重于对输入文本的处理和转换,比如写摘要和机器翻译;二是开放生成类,根据用户的需求,从零开始生成文本,比如写故事,写代码。
这类任务需要良好的模型理解和创造力,LLM在大多数情况下表现更好。
具体来说,对于撰写摘要,虽然机器评测结果显示LLM并不优于微调,但在人工评测中胜出。
在机器翻译方面,虽然LLM的平均性能略低于一些商业翻译工具,但它特别擅长翻译一些预训练前可能没见过的小语种,比如罗马尼亚语、罗曼斯语、加利西亚语等等。
在开放一代中,我们目前看到的很多作品都是基于LLM生成的,没有经过微调,比如GPT-4,实力可见一斑,不用多说。
三、知识密集型任务,强烈依赖背景知识、特定领域的专业知识或现实世界中的常识,早已超出了简单的模式识别或语法分析的范畴。
同样,让我们从结论开始:
具体来说,在一般的知识密集型任务中,LLM在几乎所有数据集上都表现较好,这是由数十亿的训练令牌和参数带来的。
比如Google提出的big model新基准Big bench的大部分任务中,其性能都优于人类的平均水平,在某些情况下甚至可以媲美人类的最佳表现,比如提供关于印度教神话的事实,从元素周期表中预测元素名称。
但是大板凳的一些任务,比如要求模型说出用ASCII艺术表示的数字,或者重新定义一个常用符号,需要模型在原义和定义衍生的意义之间进行选择,LLM性能不如微调模型,甚至不如随机猜测。

这是因为这类任务所需的知识与现实世界无关。
需要注意的是,如果“闭卷任务变成了开卷”,并且模型被赋予了检索增强能力,那么较小的微调模型会比LLM表现得更好。
除了以上三类任务,作者还详细分析了LLM缩放的知识,以及我们对以上提到的任务之外的任务和现实世界中的真实任务的选择。
这里就不一一展开了,给大家一个结论。
LLM扩展:
其他未分类的杂项任务:
现实任务:
这类任务面临的挑战包括嘈杂/非结构化的输入,用户的请求可能包含多个隐含的意图。
最后,有一些通用准则:
超过100 .
看了上面的内容,是不是觉得规章制度有点难记?
别急,就像开头提到的,作者已经把它们都浓缩成了一个思维导图,跟着它来分析就好了!(手动狗头)
八位中国作者
本文共有8位作者,均为中国人,分别来自亚马逊、德克萨斯AM大学和莱斯大学,其中5位是合著者。
合著者Jingfeng Yang目前是亚马逊的应用研究科学家。她本科毕业于北京大学,硕士毕业于佐治亚理工学院。她的研究兴趣是自然语言处理和机器学习。
此前,他还撰写了GPT-3和GPT-3.5的复制和使用指南,详细解释了为什么GPT-3的大部分复制都会失败,以及GPT-3.5和ChatGPT的最佳使用方法。
合著者之一金红叶目前是德克萨斯AM大学的博士生,毕业于北京大学,获得学士学位。他的研究兴趣是机器学习。
瑞祥唐同学,莱斯大学计算机专业四年级博士生,毕业于清华大学自动化系,学士学位。研究方向为可信AI,包括机器学习的可解释性、公平性和健壮性。
哮天·韩,德克萨斯大学四年级博士生,毕业于山东大学,获得通信工程学士学位,并在北后大学获得计算机科学硕士学位。他的研究兴趣是数据挖掘和机器学习。
冯,德克萨斯大学博士生,毕业于华中科技大学,硕士毕业于杜克大学。他的研究方向是机器学习。
此外,亚马逊应用研究科学家江、亚马逊应用科学总监冰音、莱斯大学助理教授也参与了这项研究。
纸张地址:
https://arxiv.org/abs/2304.13712
大型模型实用指南(持续更新):
https://github.com/Mooler0410/LLMsPracticalGuide
