极客号(Daydx.com)10月31日 消息:最新研究来自ISTA的科学家提出了一种创新的模型量化方法,称为QMoE,可以将庞大的1.6万亿参数SwitchTransformer压缩到令人难以置信的160GB以下,每个参数仅占用0.8位。这一方法实现了高达20倍的压缩率,为解决大型模型的高昂成本和内存需求问题提供了新的解决方案。
GPT-4等大型模型的发展使混合专家架构(MoE)成为研究的焦点。虽然MoE可以显著提高模型的准确性和训练速度,但由于庞大的参数数量,需要大量的显存才能运行这些模型。例如,1.6万亿参数的SwitchTransformer-c2048模型需要3.2TB的GPU显存。为解决这一问题,ISTA的研究人员提出了QMoE,这一框架利用专门设计的GPU解码内核,实现了高效的端到端压缩推理。
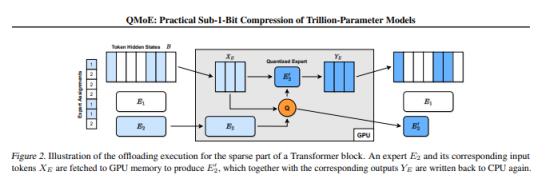

论文地址:https://arxiv.org/pdf/2310.16795.pdf
QMoE的独特之处在于采用了数据依赖的量化方法,允许在底层的位宽下实现高度压缩,同时仍能维持准确性。实验结果表明,即使在仅有2位或三元精度的情况下,与未压缩模型相比,精度的损失非常小。这一研究的成果为大规模混合专家架构模型的高效压缩和执行提供了新的可能性,将其适用于消费级GPU服务器,减少了内存开销,并降低了运行成本。
尤其令人印象深刻的是,QMoE的高效性,小型模型甚至可以在一小时内完成压缩,而大型模型如c2048也只需要不到一天的时间。虽然在执行速度方面与未压缩模型相比略有下降,但这一方法在大规模模型的压缩方面具有重要潜力。总的来说,QMoE为解决大型模型的内存需求问题提供了创新的解决方案,实现了高度的压缩和高效的执行。
然而,这项研究也存在一些局限性,因为目前公开可获得的大规模精确MoE模型数量有限,因此需要更多的研究和实验来进一步验证其适用性。这一创新性研究将有望为未来的深度学习和大型模型研究开辟新的方向。
