继meta的《瓜分一切》之后,又一个颠覆CV的模式来了!最近,来自威斯康星州麦迪逊、微软、香港科技大学的研究人员提出了SEEM模型,该模型可以通过不同的视觉线索和语言线索,一键分割图像和视频。


地址:https://arxiv.org/pdf/2304.06718.pdf.
SEEM模型是一种新的分割模型,它可以在没有提示的情况下执行开集内的任何分割任务,如语义分割、实例分割、全景分割等。
此外,它还支持视觉、文本和参考区域提示的任意组合,允许多功能和交互式参考分段。
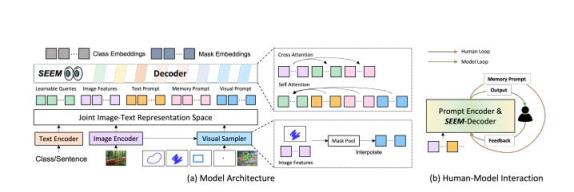
在模型架构上,SEEM采用了通用的编解码架构。它的独特之处在于查询和提示的复杂交互。
SEEM模型可以通过多模态提示一次分割所有地方的所有内容,包括图像和视频。该模型的出现将对计算机视觉领域产生深远的影响,也将对未来的技术发展方向起到指导作用。
本文内容及图片均整理自互联网,不代表本站立场,版权归原作者所有,如有侵权请联系admin#jikehao.com删除。
