国内某企业又一款大型号产品发布。
无非就是知乎,最大的中文问答社区,拥有4亿用户。
官方声明是内部测试-
不仅有第一个大语言模型“识图AI”,第一个产品也将应用到热榜。
既合理又出乎意料。
一方面,知乎有天然的大模型优势,有场景,有应用,最重要的是天然的大规模、高质量的中文数据池。纽冰也将其视为中国数据源之一,股价一度飙升近50%。
这种优势在中国是罕见的,这种产品发布也被认为是我们打了一千次电话,敦促她开始走向我们。
另一方面,在很多研究者的认知中,知乎作为一个知识问答分享平台,在这里观看和见证每一次技术革命。
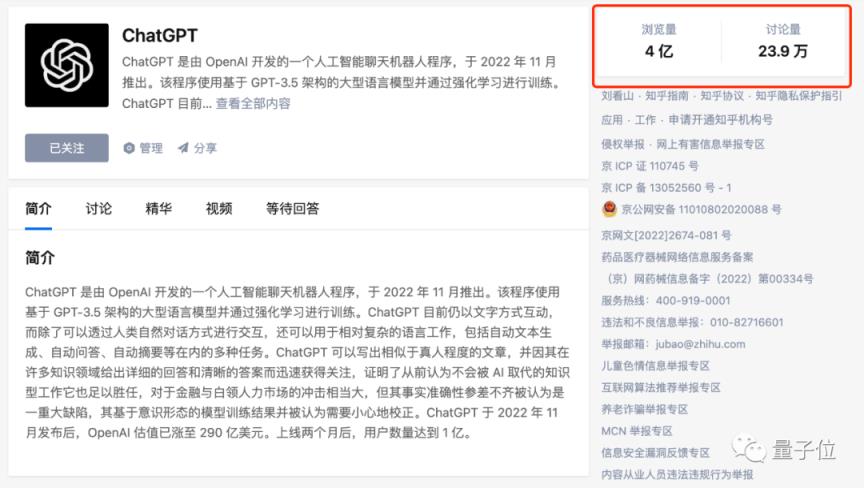
就像ChatGPT相关话题已经打破了当年AlphaGo的讨论热度,4亿次观看,近24万次讨论。

至于知乎背后相关的AI技术和布局,并不为大多数人所知。
现在,知乎主动分享一切。
并且随着产品的发布,知乎在大语言模型上的布局也首次浮出水面。
知乎大模型产品官方公布是内测。
发布会上,知乎还放出了“热榜汇总”,让等待内测的朋友们先看看吧~
你能看到的是,热门列表问题下会出现“山野守望”助手。
然后它会捕捉高质量问答的重要点,经过AI算法的整理、聚合、打磨后,展示给用户。
这样可以一边看热点问题一边获取关键信息,效率直接满满。
这背后的大语言模型CPM-Bee来自于清华的大模型创业公司face wall Intelligence,在市场上备受关注。
根据知乎联合创始人兼CTO李大海的说法,CPM-Bee是视野中最好的中文语言模型。
面墙智能联合创始人兼CEO曾杨过也给出了官方内测表现:
在内容聚合场景中,41个问题中有28个是平的。与GPT-4相比,它基本上是平的。
作为国内最早开展相关研究和探索的公司之一,创始团队来自清华计算机系自然语言处理与社会人文计算实验室(THUNLP),刘志远、孙茂松、刘洋教授分别为其联合创始人和顾问。因此在大型型号研发转化方面有着丰富的经验。
在产学研的转化中,团队首先提出了ERNIE,这是一种以知识为导向的预训练模型,他们还在国际峰会上发表了数十篇关于模型预训练、提升学习、参数高效微调等热点话题的论文。
他们还开发了几个开源的大型模型,如CPM-1、CPM-2、CPM-3。
此外,法律、生物医药等垂直领域也开发了专有大模型。自成立以来,已与法律、汽车、家电、媒体等行业领先客户达成合作,完成近千万种子轮融资。
而就在最近,侧墙智能刚刚获得由知乎领投的天使轮融资,智普AI投资。双方人士表示,本次投资合作旨在实现双方优势资源的价值创造,共同探索大型语言模型的上层应用。
由此看来,知乎大模型的布局也浮出水面:投资大模型公司,共同打造大模型应用。
据介绍,属于深度融合的关系,每天都要见面一次。
接下来,基于CPM-Bee,经过更多的反馈和迭代,新模型具有更强的逻辑推理能力和更快的训练和推理速度,将逐步应用于知乎更多的场景。
如创建、论坛、信息获取等等。
其实这条路并不陌生,就像微软和OpenAI一样。微软的产品矩阵完美契合ChatGPT的落地场景,同时可以反馈迭代大模型的能力。由此,正是两者技术和应用的深度融合,带来了震惊世界的搜索引擎、生产力和生产生活的变革,让企业和个人都能享受到AIGC带来的潜力和可能。
随之而来的问题是-
为什么走这条路?
目前国产大机型的发展远没有火热来形容。这个被认为是比以往任何变革都大十倍的机会,任何企业或机构都不会轻易错过,最近几周的新进展就证明了这一点。
不可否认,知乎此时布局大模式,选择了一条最适合自己的路——
用知乎CEO周源的话说,是AI时代新生产力的开发者,新场景的创造者。
原因还得从国产大机型的发展上拆解。
第一份中国AIGC行业全景报告显示,国内大比例模型的发展大致可以分为三条路径:基础架构层、模型层、应用层。
其中,模型层成为当前开发的关键,在一定程度上限制了上下层(基础设施层和应用层)的开发。
至于模型层开发得好不好,归根结底主要来自于计算能力和数据:计算能力是支撑背后大语言模型训练的硬件基础,而数据是直接影响模型能力乃至生成质量的关键。
尤其是中文数据,一方面中文比英文更复杂,技术难度更大;另一方面,国外的英语数据集更丰富,质量更高。而国内的中文语料库并不完善,必要时需要各个公司进行清理,耗费人力财力。
这恰好与知乎与其他平台不同的独特优势有关。
众所周知,模型的效果取决于数据的数量和质量。智虎似乎可以两者兼得。
从量来看,2022年第三季度财报显示,知识社区中的内容已经累计超过5.79亿。2022年度财报显示,问答量已累计达到5.06亿,覆盖超1000个垂直领域。
尤其是在一些专业问题上,就更加明显了。
知乎战略副总裁、社区业务负责人张宁透露了这样一组关键数据:
除了数量之外,数据的质量尤为关键。
ChatGPT发布之初,经常出现一些离谱的错误答案。“一本正经地胡说八道”是ChatGPT给人留下的第一印象。
这其实和训练数据的质量有关,数据集里混杂了很多混杂的内容。
在知乎上,众多专业人士的讨论和问答机制的筛选,构成了内容数据的高质量,甚至一些知乎内容已经直接出书。
前段时间NewBing刚发布,很多网友发现有些答案来自知乎。

周源由此将AI时代的生产力要素分为三层:应用场景、专有数据和基础模型。基于问答的论坛是很自然的应用场景。不断生成的内容、关系和知识图谱是独一无二的专有数据。
以GPT为代表的基本模型层发展迅速。结合知乎的应用场景和专有数据,可以促进大模型的快速应用。同时,知乎的专业场景也可以反馈大规模模型技术的迭代。
事实上,李大海还透露,知乎也在与各个公司合作,利用自己独特的优势助推国内大模特的发展。
除了对当前形势的考虑,这也是回归本质,顺其自然的选择。
在知乎探索大会上,周源再次谈到了知乎社区“获得感”的内容价值观——
让大家更好的分享自己的知识、经验和观点,找到自己的答案。
他认为AI最终会服务于人,赋能于人,这是人类能力的扩展。
因此,在知乎的背景下,人机共创可以帮助创作者充分发挥创造力,提高内容创作的效率和质量,从而帮助更多的用户,开阔用户的视野。
在大的模型浪潮下,已经提到了很多应用场景。知乎作为新场景的创造者,也致力于发掘更多的价值。
回顾过去的每一次技术变革,都有数百万国内从业者通过问答、话题、圆桌、观点、专栏、直播等形式在这里学习讨论、回应辩论。
因此,在某种程度上,知乎作为一个关键媒体,对国内前沿科技的发展起到了重要作用。
尤其是在这次全球ChatGPT风暴中,体验尤为明显,相关话题浏览量达到4亿次,讨论超过23.9万次。
吴恩达老师本周在此博客,呼吁大家理性看待这一波;被王会文收购、走在前列的一流科技创始人袁锦辉,正在知乎上寻找答案…
这里诞生了很多ChatGPT的衍生品:北大团队推出的ChatExcel,ChatGPT的第一个开源项目ChatRWKV,国内第一个ChatGPT检测仪…背后的开发者也做出了回应,当面解答了网友的疑惑。
一群科研人员、企业家、从业者聚集在这里,打破时间与空的壁垒,第一时间探索前沿趋势,进而推动中国前沿科技的发展。
只是现在和未来,知乎会利用自身积累的优势,以更显性的方式为中国大模式的发展做出贡献。
— End —
