近日,UC Berkeley推出了大语言模型版排位赛,让大语言模型随机对战,并根据Elo成绩进行排名。
排名数据显示,骆马以1169分排名第一,考拉排名第二。两个模型都有130亿个参数。莱昂的公开助理排名第三。
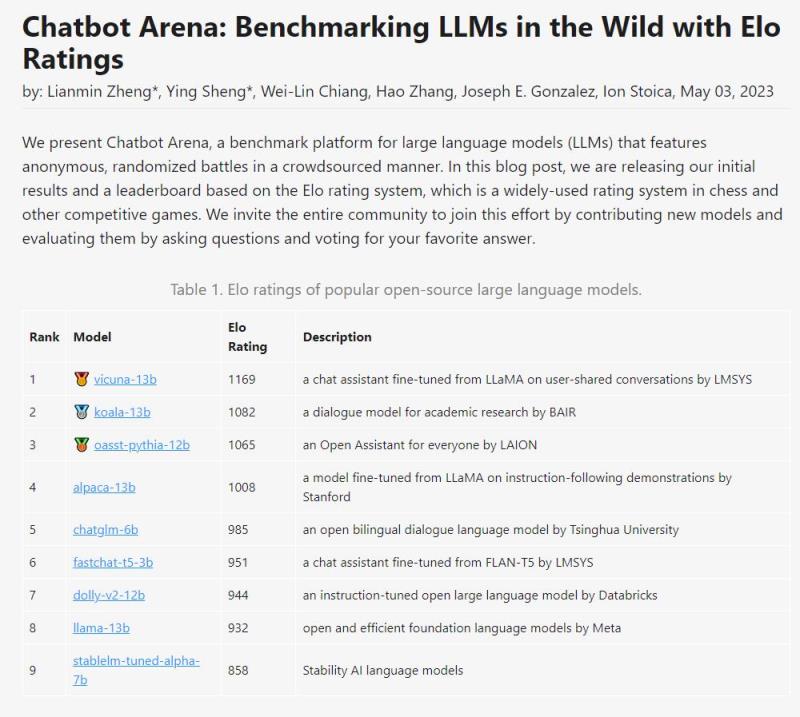

清华提出的ChatGLM,虽然只有60亿参数,但还是冲进了前五,仅落后羊驼130亿参数23分。
相比之下,meta的原驼只排在第八(倒数第二),而Stability AI的StableLM得分只有800+分,排名倒数第一。
这种排位赛可以让人们更好的了解各种聊天机器人的性能,也可以促进大语言模型的发展。排位赛会把这些国内外的“闭源”车型拉进来。目前所有评测代码和数据分析均已公布。
团队表示,不仅会定期更新排位名单,还会优化算法和机制,并根据不同的任务类型提供更详细的排名。
本文内容及图片均整理自互联网,不代表本站立场,版权归原作者所有,如有侵权请联系admin#jikehao.com删除。
