一整首歌写在一个段落里,甚至男女唱(跳)rap的时候。
男女说唱音频:00:0000:30
Google最新款MusicLM一经推出就惊艳全场,很多网友惊呼:这是我听过最好的音乐作曲。


它可以根据文本生成任何一种音乐,无论是根据时间、地点、年代等各种因素进行调整,也可以为剧情、世界名画提供音乐,生成人声说唱口哨。
比如这个《呐喊》。

它在一段取自百科全书的描述的提示下创作了这样一段音乐。
(蒙克在一次幻觉体验中感受到并听到了整个大自然的尖叫声,并以此为灵感,描绘了一个惊慌失措的生物,它既像尸体,又让人联想到精子或胎儿,其轮廓与血红色天空的螺旋线条相呼应空。)
ViT(视觉变形者)的作者说,听了一段关键词为“平静舒缓”“笛子吉他”的生成音乐后,他真的平静下来了。
难免有同事说这比ChatGPT更值得我关注,Google也差不多解决了音乐生成的问题。
毕竟MusicLM依靠的是28万小时音乐的训练数据库。其实从发布的Demo来看,MusicLM的能力不止于此。
你可以即兴表演五分钟。
可以看出,MusicLM最大的亮点是根据丰富的文本描述生成音乐,包括乐器、音乐风格、适用场景、节奏和音调,以及是否包含人声(哼唱、吹口哨、合唱),从而生成一段30秒的音乐。
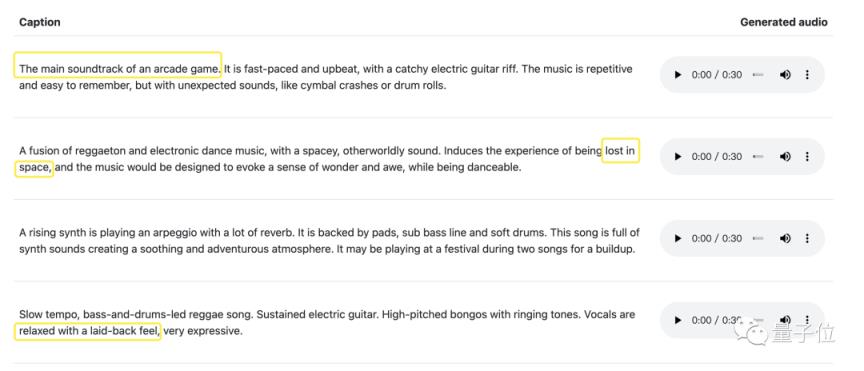
哪怕只是那种暧昧的气氛,“迷失在too 空”和“轻松闲适”;或者可以直接用在一些实际场景中,比如“街机游戏评分”和绘画评分。
此外,MusicLM还具有创作长篇音乐、故事模式和调整旋律的能力。
在长音乐方面,它可以即兴创作5分钟,哪怕提示只有一个字。
比如只有在Swing的提示下,听起来好像我真的很想立刻下班去跳舞。(布施)
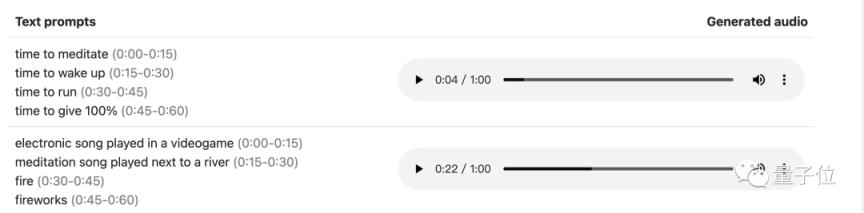
在故事模式中,不同的情绪标记甚至可以在几秒钟内生成,即使情况之间没有联系…
更神奇的是,它还有很强的实用功能。
一方面可以把旋律提示和文字提示结合起来,让音乐调整得更精细。有点像改变甲方爸爸的需求。
另一方面,也可以根据具体的乐器、场所、流派、年代,甚至音乐家的演奏水平来生成。
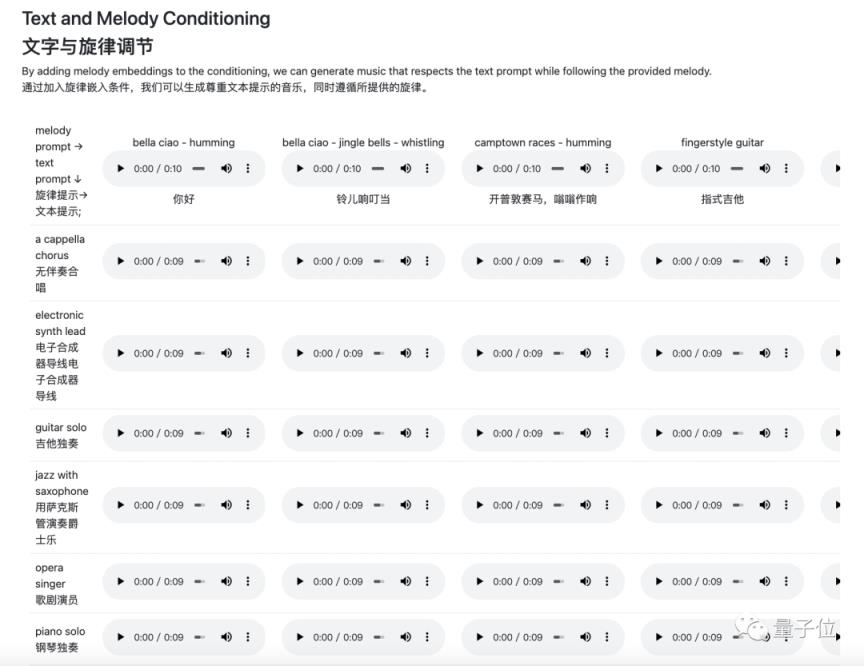
幕后生成模型MusicLM
不过据说AI生成的音乐模型不在少数,谷歌自己之前也推出过类似的模型AudioLM。
这次的MusicLM有什么不同?

据研究团队介绍,主要贡献有三点:
生成模型MusicLM。
将该方法推广到其他条件信号,如根据文字提示合成的旋律,生成5分钟的demo。
第一个专门为文本到音乐生成任务设计的评估数据集MusicCaps发布了。
首先,MusicLM是Google三个月前提出的AudioLM模型的扩展。
AudioLM不需要转录或标记。只需听音频,AudioLM就能生成与提示风格一致的连贯音乐,包括钢琴声或人声对话等复杂声音。
最新的MusicLM使用AudioLM的多阶段自回归建模作为生成条件,并在此基础上进行扩展,使其可以通过文本提示生成和修改音乐。
它是一个分层的序列对序列模型,可以通过文本描述产生频率为24kHz的音乐,并保持这个频率几分钟。
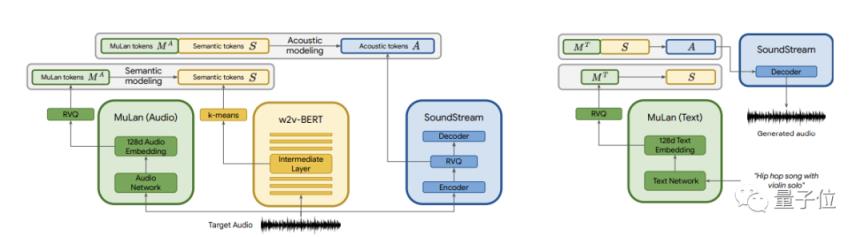
具体来说,研究小组使用了三个模型进行预训练,包括自监督音频表示模型SoundStream,它可以在低比特率下压缩一般音频,同时保持高重建质量。
还有语义标记模型w2vBERT促进连贯的生成;音频文本嵌入模型木兰,可以将音乐及其对应的文本描述投射到嵌入空(消除训练时对文本的不同需求),允许在纯音频语料上训练,以应对训练数据有限的问题。
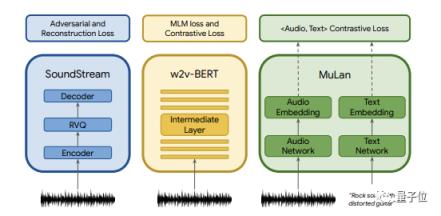
在训练过程中,他们从纯音频训练集中提取了木兰音频标签、语义标签和声学标签。
在语义建模阶段,他们使用木兰音频标签作为条件来预测语义标签。然后,在声学建模阶段,基于木兰音频标记和语义标记来预测声学标记。
每个阶段都被建模为一个序列-序列任务,并使用一个单独的解码器转换器。
在推理过程中,他们使用从文本提示中计算出的木兰文本标记作为调整信号,并使用SoundStream解码器将生成的音频标记转换成波形。
经过28万小时的训练,MusicLM终于学会了以24kHz的频率生成音乐,即使用来生成音乐的文字非常迂回。
类似于“迷人的爵士歌曲和令人难忘的萨克斯独奏家和独奏者”或者“柏林90年代的低音和强劲的电子音乐”。
研究小组还引入了高质量的音乐数据集MusicCaps,以解决任务缺乏评估数据的问题。
MusicCaps由专业人士共同打造,涵盖5500个音乐-文字对。研究小组公布了这组数据,以供进一步研究。
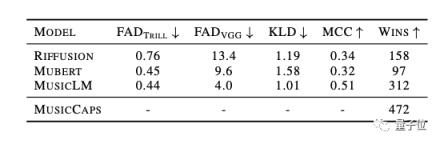
经过这样的一套操作,通过量化指标和人工评测,MusicLM在音质和文字契合度上都优于上一代音乐AI。
不过谷歌研究团队表示:目前没有发布MusicLM的计划。
原因很简单。除了训练过程中不可避免的样本质量失真,还有两个关键点。
第一,虽然MusicLM在技术上可以生成合唱、和声等声音,但是仔细听的话,生成音乐的歌词有些勉强算是音乐,有些根本就是没人听得懂的外星方言。
此外,研究团队发现,该系统生成的音乐中,约有1%是直接从训练集中的歌曲复制而来的——这足以阻止MusicLM的发布。
此外,一些批评者质疑在有版权的音乐材料上训练AI模型是否合理。
不过团队在论文中介绍了下一步的趋势,主要集中在歌词生成、提高提示文本的准确率和提高生成质量。
复杂音乐结构的建模也将成为团队的重点方向之一。
音频生成人工智能
这项研究背后的团队是谷歌研究院。
合著者Timo I. Denk是谷歌瑞士公司的一名软件工程师,他的日常工作就是使用ML来理解音乐。
这里再多说两句,在MusicLM的论文中,研究小组提到MusicLM在质量和及时合规性方面都优于之前的系统。
有哪些「以前的系统」?
一个是Mubert,已经在Github中开放了一个API。它是一个文字转音乐的AI,其系列产品包括根据现有标签生成音乐的Mubert Render,Mubert Play等等。
还有Riffusion,基于AI画图,但是应用到声音上。
换句话说,Riffusion的工作原理是首先构建一个索引谱图集,其中包含代表谱图中捕获的音乐风格的关键字。
在声谱图主体上训练时,Riffusion使用了同样的稳定扩散的方法——干扰噪声,获得与文本提示相匹配的声波图像。
还有针对音乐制作人和音乐人的AI音频生成工具舞蹈扩散,可以自动生成音乐的ML框架点唱机…
比如说,不要整天盯着ChatGPT看。如果AIGC的下一个出路是音乐一代会怎样?
参考链接:
[1]https://Google-research . github . io/seanet/musiclm/examples/
[2]https://arxiv . org/pdf/2301.11325 . pdf
[3]https://TechCrunch . com/2023/01/27/Google-created-an-ai-can-generate-music-from-text-descriptions-but-wot-release-it/
