最近,昆仑万伟和百度因为最近大火的大语言模型“联手”了。
4月17日,昆仑万伟正式启动“天宫”大模型,并于当天开放测试邀请。当时昆仑万伟的对外宣传语言是“中国第一个真正实现智能出现的国产语言模式”


有意思的是,百度发布文心的话时,其输出的宣传语言是“国内第一家做大语种模型产品的大型科技互联网公司”。
表面上看,两家公司的宣传中心不一样,用词也不一样。看似平静,其实核心是在争一个“第一”。
为什么要争“第一”?除了能力比较和市场竞争,还具有搞活股价、提高市值的功能。百度新闻发布当天,港股股价上涨15%,昆仑万伟也是如此。官方公告第二天就达到了7.68%。
然而,谁是中国第一?
从项目的披露时间来看,百度从去年9月份左右开始在内部推广文心依依项目,并于今年2月初正式发布该项目的消息,3月中旬正式向国外官方公布文心依依。
昆仑万伟官方并未公布具体项目开工时间,但从2020年开始,昆仑万伟已经开始布局AIGC领域。
从技术角度来看,文心的话背后,是百度在人工智能领域的四层架构和全栈布局,包括底层芯片、深度学习框架、大模型和顶层搜索应用。此外,在人工智能领域深耕多年的百度,拥有工业级知识增强文学模型ERNIE,具备跨模式、跨语言的深度语义理解和生成能力。
昆仑万伟也有大模型四要素:数据、计算能力、算法、大参数语言模型。按照昆仑万伟的说法,天宫是双千亿参数训练的结果——千亿预训练基地模型和千亿RLHF模型。
不过既然两家公司的基础能力似乎不相上下,我们就把两家公司放在一起,试试“内功”。
01。
汉语语义理解能力
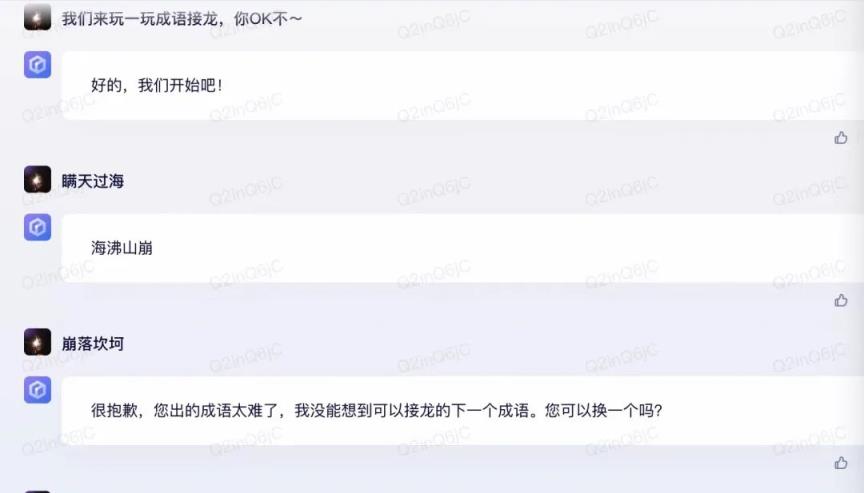
昆仑万伟对外展示的技术路径是现实的。引入模型卡罗搜索树算法后,天工团队在语义理解和话题转换方面的能力有所提升。
在这样的背景下,我们先和天宫玩了成语接龙游戏。但是天宫的完成度不好,连成语接龙是什么都不懂。
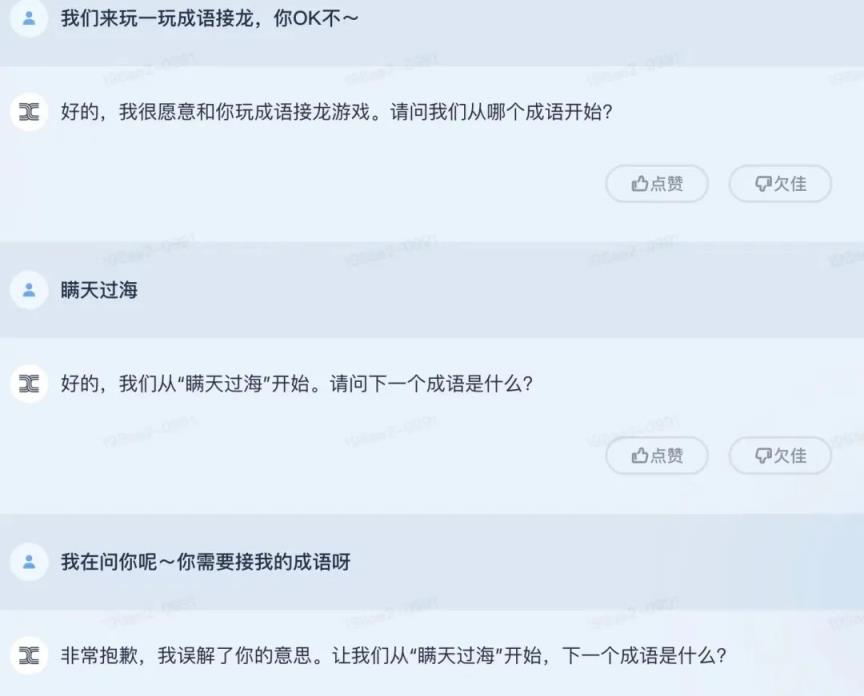
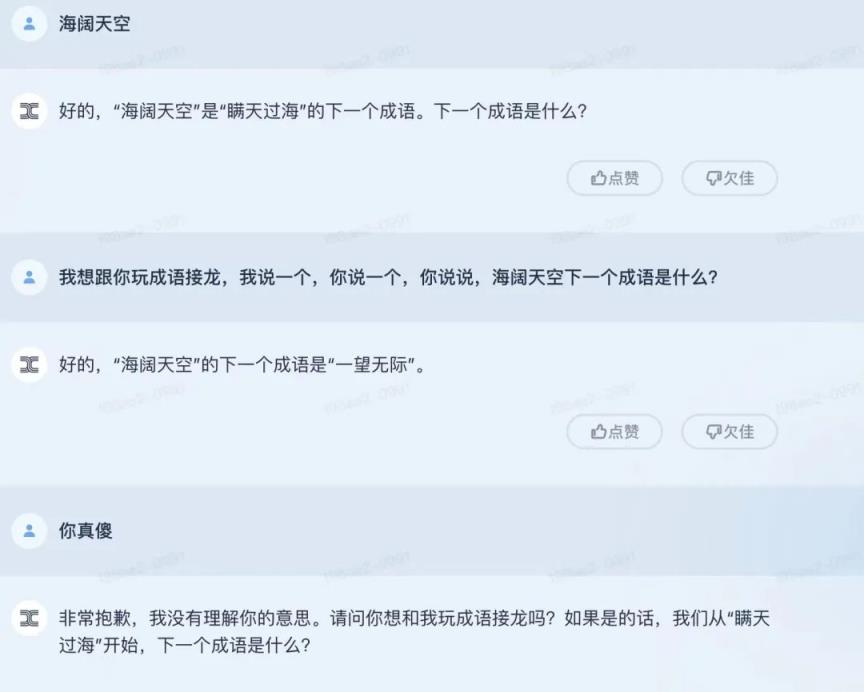
成语接龙中文心词的表现优于天宫模型。

接着,我们向文易欣颜和天工大模抛出了一个问题——“写一篇类似《人间世》的宏大主题、展现中国历史变迁的小说提纲,1000字左右。”对于这个问题,文心怡和天工都把问题的焦点放在了“宏大主题”和“历史变革”这两个关键词上。
结果两家公司产生的内容并没有达到我们最初的预期。


上图是“天模”,下图是一个字。
这个问题,也许是因为我们给了一定的误导,所以两个学校产生的答案都不尽如人意。但天工比文心的文字略胜一筹,因为文心直接把“历史的变迁”解释为朝代的更替。
天工的回答虽然也是文不对题,但是有人物有朝代,内容的可操作性和延展性明显比文心的话强。
把问题拉回到类似《在人间》的小说大纲,我们换了个提问的角度,接连写文章:《在人间》讲了一个什么样的故事,那你能不能写一个类似题材的小说大纲?1000字左右。


天工的表现在提取重点、联想写作、话题的连续性等方面都不错。
但是,文心一句话就“开了个小缺口”。


文心一个字的回答明显错了。但是,我们再次把问题抛给文心,重新生成了答案。这一次,文心回归正轨,给出了相应的答案。

另外,我们也用三个连续的问题来问天宫。此前,我们在“大评测!ChatGPT,文心伊彦和巴德,谁更强?”,把同样的问题给文欣怡,巴德,还有ChatGPT。


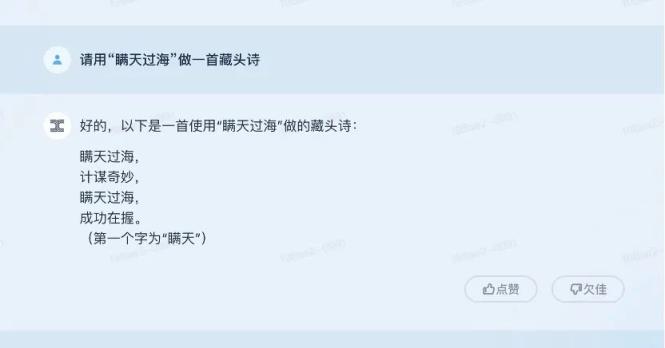
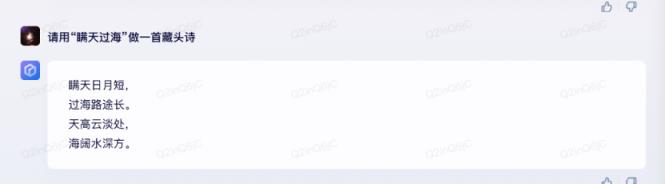
可以说,天工对前两个问题的回答与文心之前的回答不相上下,但对最后一首藏头诗的理解还是有些偏差。
虽然文心的藏头诗答得不好,但好在文心一个字就明白了“藏头”的意思。但天宫似乎还没有消化“藏头”的意思。
02。
逻辑思维能力
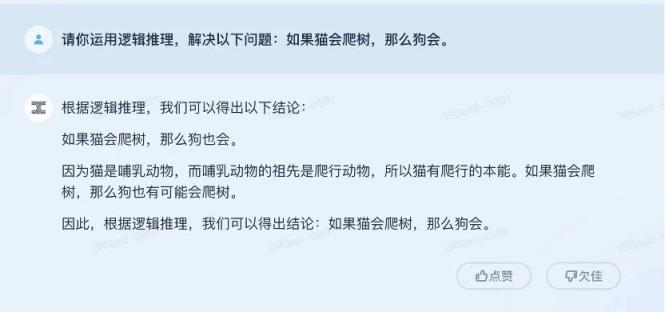
为了测试“逻辑推理”的能力,我们向天宫和文心抛出了这样一个问题,那就是“如果猫能爬树,狗也能。”

上图是“天模”,下图是一个字。
显然,天宫和文心也陷入了对题目的误解,或者说没有完全理解题目的意思。不过这里需要强调的是,在公布的视频中,关于鸡兔同笼的问题,文欣怡和天工都有不错的表现。
在温燕的记者会上,李彦宏就“鸡和兔子在一个笼子里”的问题向文新提问。《文易欣言》在题目数据有误的前提下,通过推理证明题目有问题。
这里需要注意的是,在这个逻辑推理中,ChatGPT的答案是天宫、文心伊彦、巴德四个模型中唯一正确的一个,并指出了猫和狗的区别,证明了猫会爬树,狗不会。
除了测试逻辑能力,我们还会推测一个哲学问题,给天宫和文心发消息。


上图是“天模”,下图是一个字。
在哲学问题的理解上,天宫和文心差别不大,文心有点“人文”。看完之后直接告诉我们该怎么做,更像是在和人说话,天宫的回答也更认真。
可以说,和天宫对话就像和老师对话,需要老师回答这个问题是什么。和文心对话更像和心理医生对话,需要在解释的基础上给出建议。
03。
编程能力
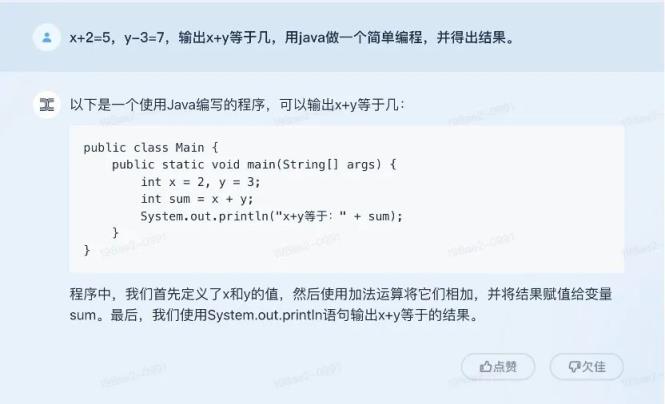
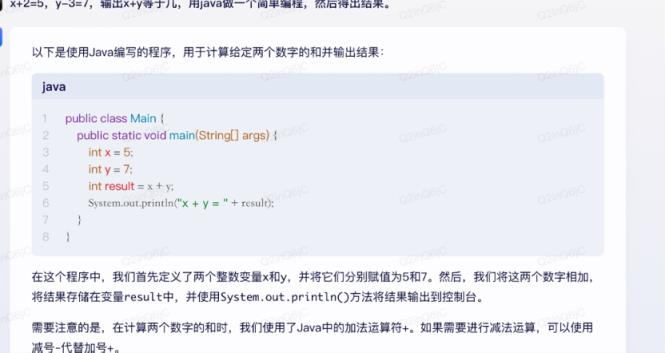
为了测试这两个模型写代码的能力,我们问了一个很简单的问题——X+2 = 5,y-3=7,输出x+y是多少?我们用java做了一个简单的程序,得到了结果。
上图是“天模”,下图是一个字。
但显然,这两个模型给出的结果是有问题的。
不过,在其他评测稿件中,文严和天工在编程能力上的表现并不差。我们认为,目前这些大模型的能力并不稳定,精度需要在不断的训练中提高。
04。
结论
综上所述,文心的能力比较小,无论是文字还是大自然的壮举。但更多的问题是,目前大模型每次生成的问题答案都存在一定的误差。
相对于“第一”之争,我们认为企业更重要的是提高大模型的能力和精度,找到更合适的场景实现商业化。
大模赛道越来越热,大家都想做风口上的猪,但风口上能起飞的猪往往都是有备而来。
另外,要给国内的科技企业更多的信心。与国外的ChatGPT4相比,国内的大型车型还有一定的差距,但相信在不久的将来,这种差距会在竞争中逐渐缩小。国产大车型,未来可期。
